CCA-F Trainer · How it works
Six techniques. One job.
Every feature is built to close the 77% of the CCA exam that Anthropic's official study guide doesn't cover.
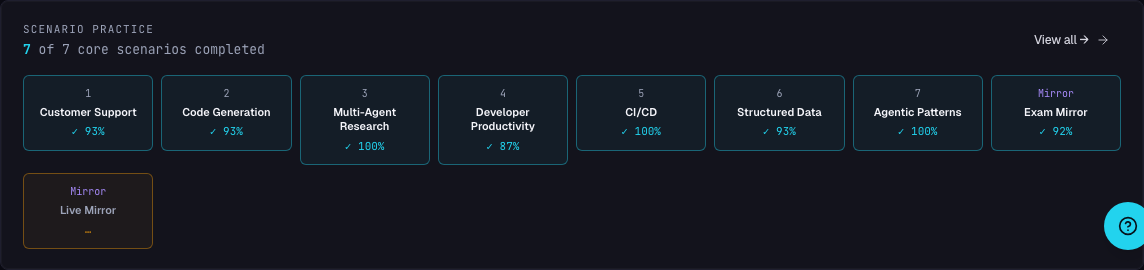
- 1Per-scenario completionAll seven core scenarios tracked individually. The number ticks up as scenarios are completed — gaps stay visible until you close them.
- 2Last-session accuracy per tileEach scenario shows the most recent session's accuracy. Outliers (the 87% next to a row of 100%s) surface the next scenario to drill.
- 3Realistic Scenario sets visible tooFeatured high-realism question sets sit alongside the seven core scenarios so final-review priorities are obvious at a glance.
24 questions measure where you actually stand before the system adapts anything.
Self-reported confidence levels don't predict exam performance — observed answers do. The diagnostic runs 24 questions distributed across all five CCA exam domains in the same proportions they appear on the real exam, so the initial readiness signal reflects the actual exam blueprint rather than question availability. Your dashboard score is ready the moment you finish; the system waits for the computation before surfacing a number.
- ↳All five CCA exam domains covered, weighted to match real exam proportions
- ↳Domain gaps identified before you spend time drilling the wrong areas
- ↳Readiness score on the 100–1000 scale, ready immediately on completion
- ↳Coach withholds personalization during the diagnostic — it observes, doesn't pre-empt
- ↳Every technique that follows is seeded by this baseline, not by how you felt going in
No survey, no "rate your comfort level" — just 24 questions that tell the system what it needs to know.
Eight official scenarios — the same ones named in the exam guide — each drillable in isolation.
The CCA-F exam is scenario-first: every question arrives inside a multi-page production-system narrative shared across that scenario's question set. Practicing in isolated scenario sessions trains the contextual reasoning the exam actually tests, not recall of definitions detached from context. Per-scenario tracking surfaces coverage gaps immediately — you can see which scenarios have been drilled and which have been avoided.
- ↳All eight official scenarios available for individual drill sessions
- ↳15 questions per scenario session, matching the exam's per-scenario structure
- ↳Per-scenario mastery visible on the dashboard — gaps are explicit, not inferred
- ↳Full Simulated Exam weights scenario selection toward your least-practiced scenarios
- ↳Multiple question-set versions per scenario — re-drilling returns fresh questions
The exam presents 4 of the 8 scenarios at random. Drilling all eight removes the possibility of being caught off-guard by the draw.
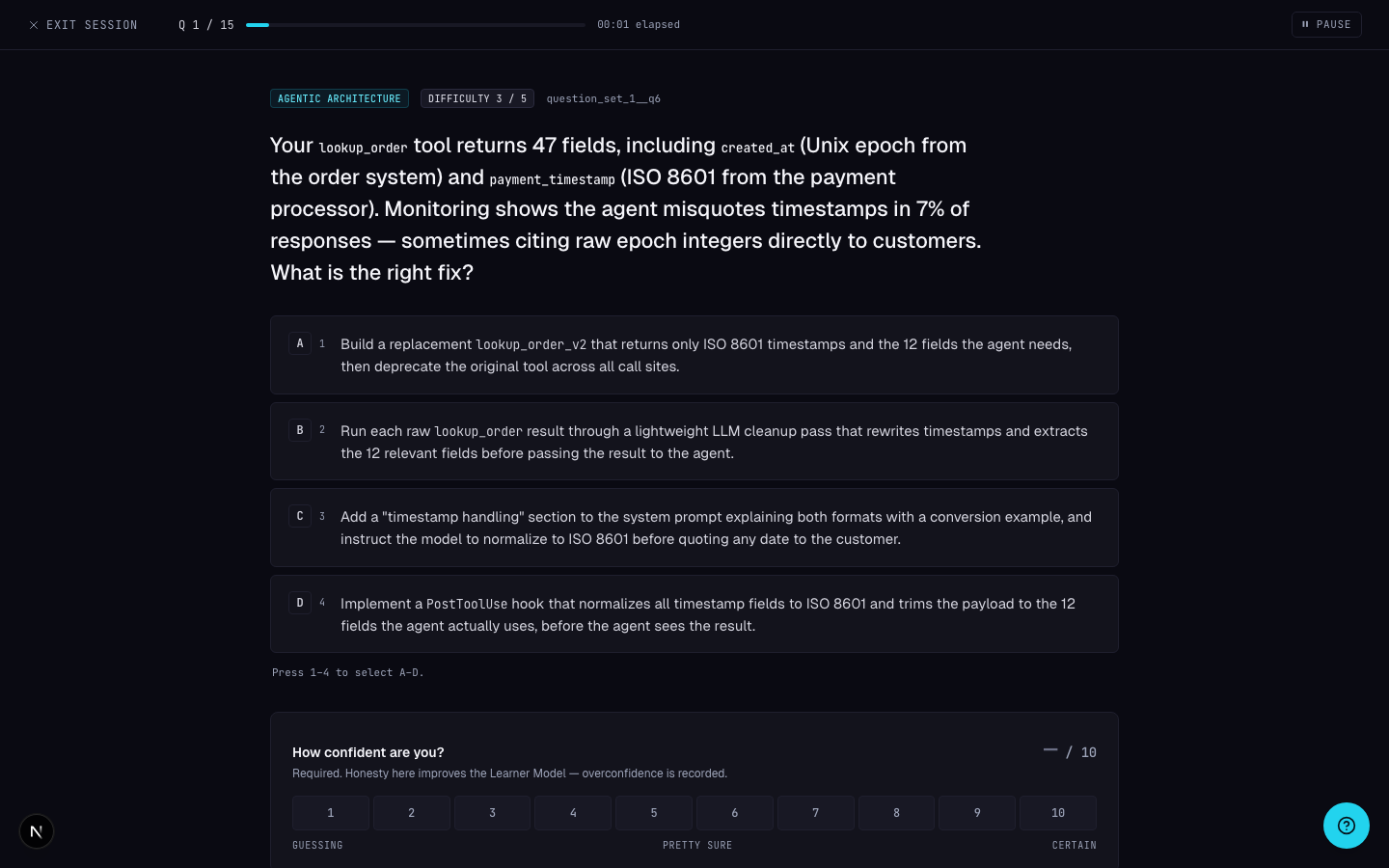
- 1Per-session progressQ 1/15 across the top — the same 15-question session structure the exam uses. No surprise length, no surprise format.
- 2Difficulty + source visibleEvery question carries its domain, difficulty, and source tag (question_set_1__q6) so it's obvious which slice of the curriculum you're being tested on.
- 3Confidence required before submitThe 1–10 confidence selector is mandatory. Overconfidence on wrong answers gets a higher retake priority than uncertainty on wrong answers.
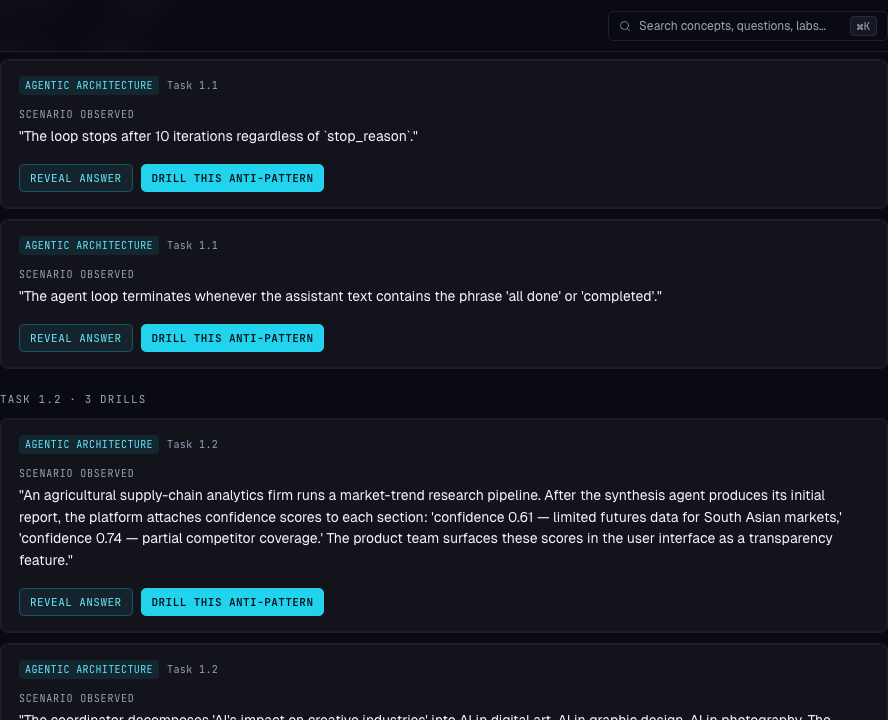
- 1Domain + task tagged per cardEvery drill card carries its domain (Agentic Architecture) and task statement (Task 1.1) so it's obvious which exam objective the trap maps to.
- 2Scenario Observed, in plain textEach card opens with the wrong design choice as a verbatim scenario — the exact shape of the trap real exam questions wrap around.
- 3One-click drill from any cardReveal Answer for the explanation, or Drill This Anti-Pattern to launch a focused practice session built around that specific trap.
86 drill cards built around the decisions the exam is designed to tempt you into making.
Multiple-choice architecture questions are won by reliable elimination as much as by selecting the right answer. The exam specifically constructs distractors from plausible-but-wrong design choices — terminating on natural language signals instead of stop_reason, resolving ambiguity automatically instead of escalating, adding tools until coverage feels complete. Each drill card presents the trap as a Scenario Observed → Why This Is Wrong → Right Pattern sequence, matching the rhythm of real exam question stems and explanations.
- ↳86 reference cards spanning all five CCA exam domains, each tagged to a specific exam task statement
- ↳Archetypes expanded from the latest real-exam signal analysis, including patterns absent from the official study guide
- ↳Each card surfaces the tempting wrong decision and explains exactly why the architecture fails
- ↳Drill any card directly from the curriculum browser — one click launches a practice session for that specific pattern
- ↳Every curriculum concept carries a source confidence tag — high, medium, or low — based on directness of Anthropic documentation
Knowing the right answer is table stakes. Recognizing why the wrong answer looks convincing is what the exam actually tests.
The system watches what you get wrong with high confidence — those are the answers that fail on exam day.
No comfort-level sliders, no topic self-rating. Most prep apps ask you to identify your weak areas, then route accordingly — there's no good evidence that self-report predicts what you'll actually miss. The Learner Model tracks observed accuracy, confidence ratings, and forgetting patterns across every session, then prioritizes the concepts where your confidence outruns your actual performance. Overconfident wrong answers get higher priority than uncertain wrong answers, because overconfidence is harder to self-correct.
- ↳Overconfidence detection surfaces the mistakes you'd make confidently on exam day
- ↳Drill selection interleaves weak areas across domains — multiple gaps surface together, not one domain exhausted at a time
- ↳Recommendations update after every session, not at chapter or module boundaries
- ↳Mastery thresholds calibrated to the actual CCA passing bar, not generic correctness percentages
- ↳All routing inputs are performance-derived — nothing adapts to how you describe yourself
We don't ask if you're a visual or auditory learner — we observe what actually works for you and adapt to that. No personality quiz, no self-report routing.
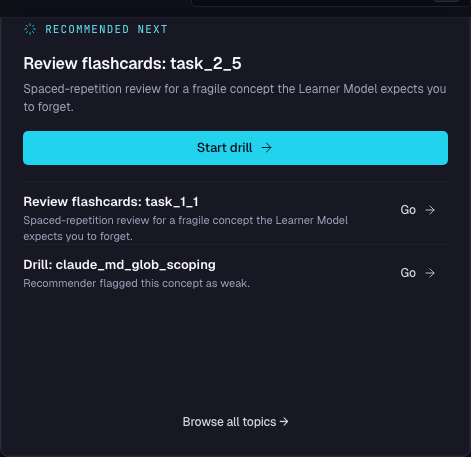
- 1Top recommendation, observedSurfaced from the Learner Model based on actual performance — never from a self-rated comfort slider. The card explains why it was picked.
- 2One click into the drillThe Start drill button launches the exact session being recommended — no menu hunting, no "figure out which mode you need."
- 3Why-this-card transparencyEach recommendation states its trigger — fragile concept, weak domain, due review — so the routing is auditable, not a black box.

- 1100–1000 readiness, real-timeReadinessRing renders on the actual exam scale. 720 = pass; we target 820 in our (harder) sim, which Anthropic says ≈ 900 on their practice exam.
- 2Bucket label updates liveNot Ready → Approaching → Exam Likely → Strong. The headline reflects where you actually are so the bottleneck is named, not buried.
- 3Pass-threshold pinned at 720The same 720 / 1000 line you have to clear on exam day is rendered alongside your score — no ambiguity about what's enough.
One readiness score on the 100–1000 scale, built from six independent performance signals.
A single accuracy percentage cannot distinguish a learner who performed well on flashcards from one who can sustain that performance across a 60-question proctored exam. The readiness score combines six factors — scenario accuracy, domain coverage, calibration, lab completion, flashcard retention, and full-exam endurance — weighted against the same scale the real exam uses, with the same 720 pass threshold. The dashboard shows the per-factor breakdown, so the bottleneck is explicit: not just whether the score moved, but which factor is holding it.
- ↳Six-factor composite displayed on the 100–1000 scale — same scoring system as the real exam
- ↳720 threshold visible at all times, the same number that matters on exam day
- ↳Per-factor breakdown identifies exactly which dimension is limiting the score
- ↳Recent simulated exam performance contributes a bonus that decays over 14 days — study recency is a signal
- ↳Endurance factor captures whether accuracy holds across a full exam, not just in short sessions
Calibration — how often your confidence level matches your accuracy — is one of the six factors. Overconfidence predicts exam-day failure more reliably than raw wrong-answer rate. The app targets ≥ 720, and shows you what your data says.
Seven labs, three scaffolding modes — pick the level of support that matches where you actually are.
Anthropic's own FAQ is direct: unless you already have hands-on experience with Claude Code, the Agent SDK, the API, and MCP, the exam guide alone is not enough to pass. The labs cover that applied layer. Each lab ships in three modes — Guided (step-by-step, with the rationale behind each step), Mid (milestones and checkpoints, implementation detail is yours), and DIY (acceptance criteria only). After you submit, a Coach Review Agent scores your work against the rubric, flags documented failure modes, and suggests the next step.
- ↳Three scaffolding modes per lab — re-take the same lab at a harder mode once you've passed the easier one
- ↳Labs cover the hands-on competency areas the exam tests directly
- ↳Coach Review Agent grades submissions per-criterion, not a self-check
- ↳Scaffolding mode recorded per attempt — the system knows if you've never attempted DIY
- ↳Four labs map directly to official Anthropic exam preparation exercises
Labs run in your own development environment — paste your output back in, and the Coach Review Agent takes it from there.
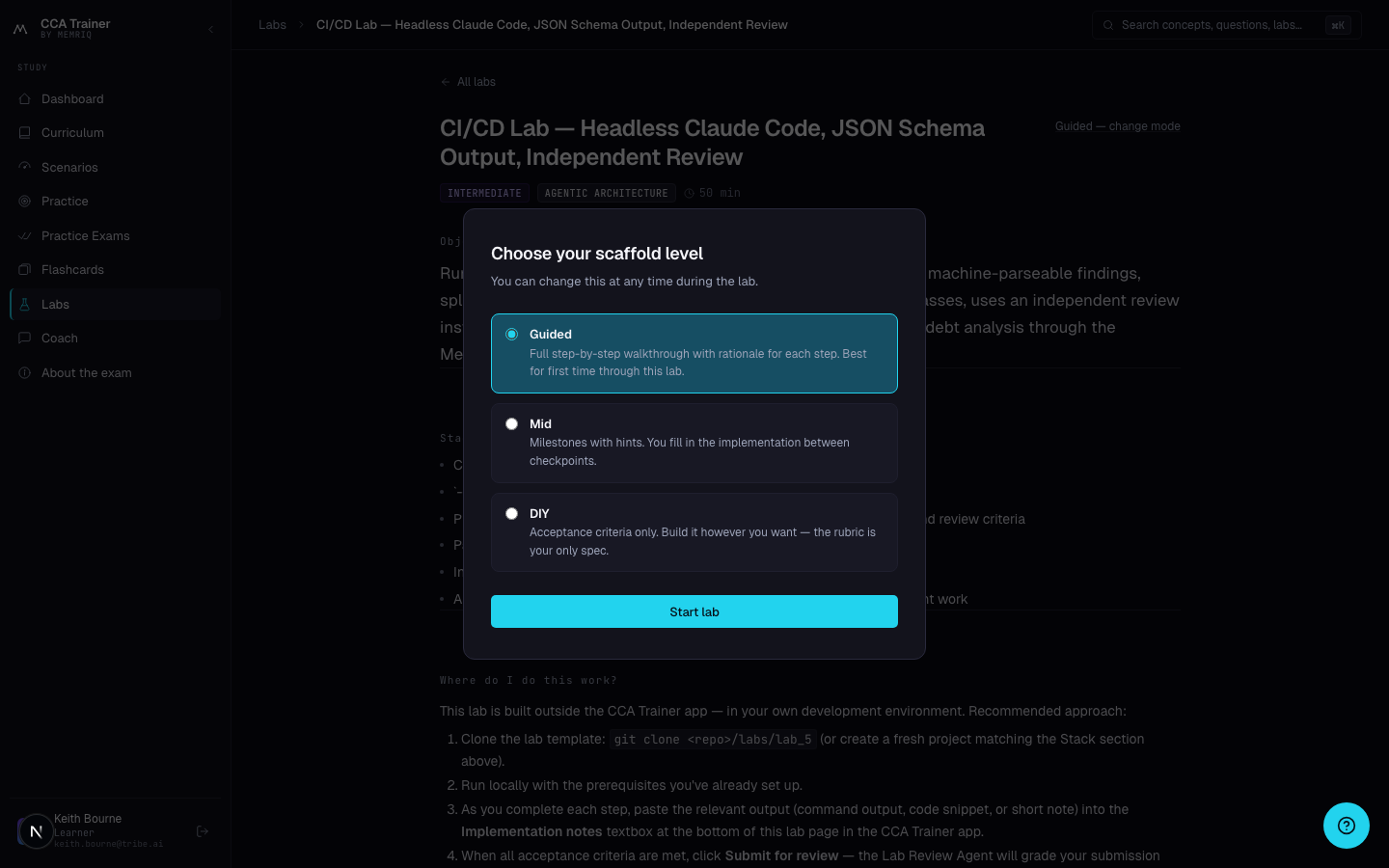
- 1Three modes per labPicked at lab start, changeable any time. Re-take the same lab on a harder mode after passing the easier one to verify mastery.
- 2Guided: full step-by-stepWalkthrough with the reasoning behind each step. Best first pass — see how the pattern is supposed to feel before you do it cold.
- 3DIY: acceptance criteria onlyHardest mode. The rubric is your spec. Used to verify you can implement the pattern without scaffolding before exam day.
How the system learns about you
Built on learning-science primitives — not static question banks.
Recency-weighted Bayesian mastery per concept
Each of the 30 curriculum concepts has a mastery estimate updated after every answer. Evidence decays 5% per day (DECAY_PER_DAY = 0.95), so recent answers carry more weight than older ones. A Bayesian prior (50% mastery, strength = 2 virtual attempts) prevents overconfident estimates from sparse data.
Overconfidence detection on every answered question
Every answer includes a 1–5 confidence rating. The system computes calibration error per concept: avg(correctness) − avg(normalised_confidence). Concepts where confidence exceeds performance by more than 0.15 are flagged as overconfident and prioritised for drilling — because overconfidence on exam day is harder to self-correct than uncertainty.
Ebbinghaus-derived forgetting risk drives review timing
Retention is modelled as R(t) = e^(−t/S) where stability S scales with mastery (1–30 days). A fully-mastered concept is stable for ~30 days; an unmastered one forgets within ~1 day. Review is recommended at the 70% retention threshold. Concepts approaching forgetting surface in the recommendation queue before you would naturally think to revisit them.
Six independent signals combine into one 100–1000 readiness score
Scenario accuracy (35%), domain coverage (20%), confidence calibration (15%), lab completion (15%), flashcard retention (10%), and full-exam endurance (5%) are combined into a single score on the same 100–1000 scale the real exam uses. The breakdown shows exactly which factor is limiting your score — not just whether the number moved.
Ready to start
The Diagnostic Review takes about 20 minutes and gives you a domain-by-domain baseline before any practice session.